
大数据集群高可用之hdfs
hdfs如何保证高可用
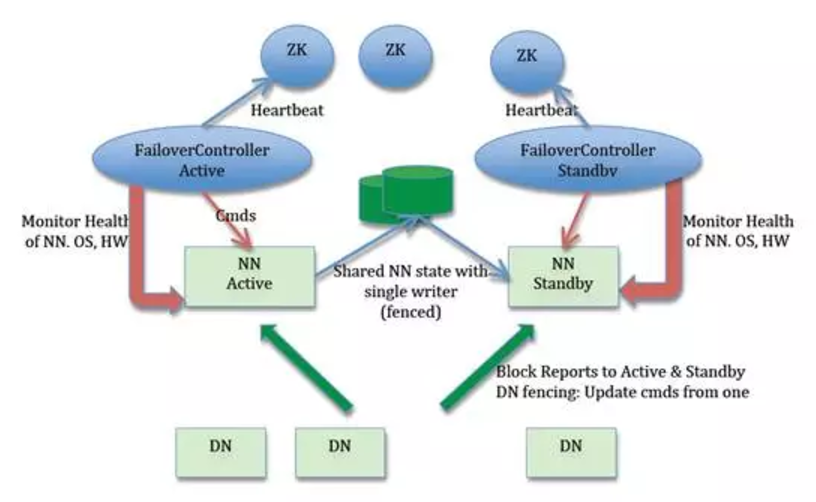
从上图中我们可以看到,启动的时候,主备选举是利用 zookeeper 来实现的, hdfs namenode节点上的 ZKFailoverController 进程, 主要负责控制主备切换,监控 namenode进程是否还活着, 连接 zookeeper进行选举,并且控制本机的 namenode 的行为,如果发现zookeeper的锁节点还没有被抢占创建,就创建锁节点,并把本机的 namenode 变成 active 节点, 如果发现锁节点已经创建,就把 本机的namenode变成standby节点。
如果 ZKFailoverController 发现本机的 namenode 已经挂掉了, 就删除zookeeper上的节点,standby 上的ZKFailoverController感知到删除事件, 就升级本机的namenode成为主节点。
如果 active节点超过 Zookeeper Session Timeout 参数配置的时间没有连接 zookeeper, 同样被认为主节点已经挂了, standby 节点也会升级成为主节点
hdfs 如何进行主备切换
与单机文件系统相似,HDFS对文件系统的目录结构也是按照树状结构维护,Namespace保存了目录树及每个目录/文件节点的属性。除在内存常驻外,这部分数据会定期flush到持久化设备上,生成一个新的FsImage文件,方便NameNode发生重启时,从FsImage及时恢复整个Namespace。
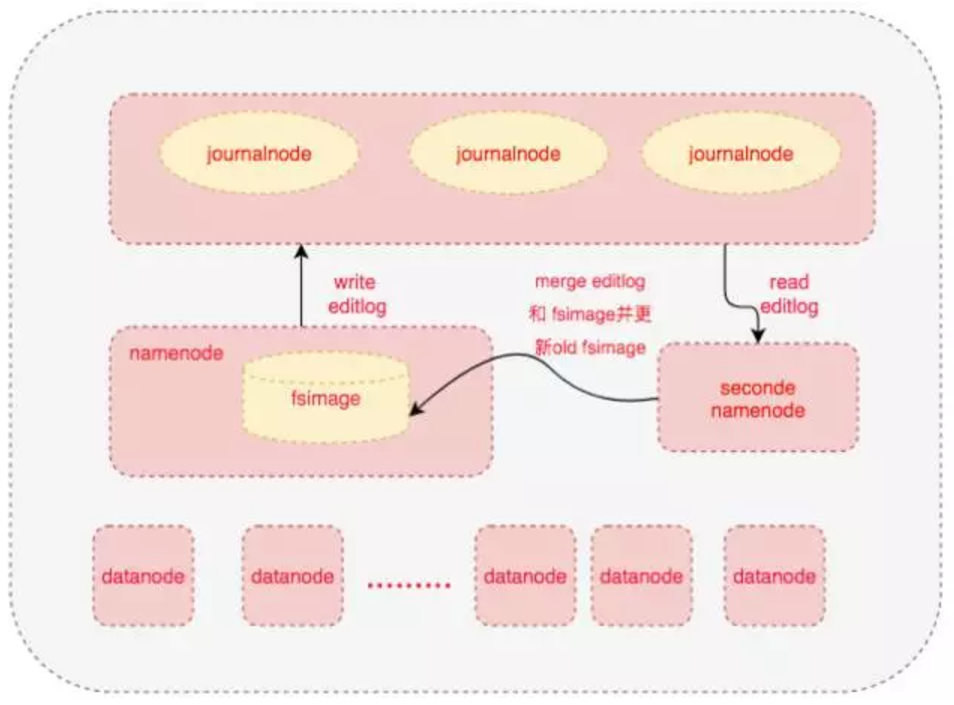
上图我们可以看到基于 journalnode 进行共享元数据, jounalnode中保存着 editlog,也就是对文件元数据的操作日志,比如用户(hdfs dfs rm /a.txt)删除一个文件, 就产生了一条操作日志,作用到命名空间后,a.txt 这个文件就被干掉了,这个日志就类似于数据库中的 redo 日志, standby节点 周期性的从journalnode中拉取 editlog, 然后从上一次checkpoint的位置开始重放,在内存中将操作结果合并到老的fsimage(命名空间), 并更新checkpoint位置。 最后把合并后的fsimage 上传到 active namenode 保存替换老的fsimage文件,
NameNode 处于 active和standby状态时候,扮演的角色是很不同的,
-
active 角色, 把用户对命名空间的操作作为 editlog 写入 journalnode 集群
-
standby 角色,EditLogTailer 线程 从 journalnode 上拉取 editlog日志, StandbyCheckpointer 线程把 editlog合并到 fsimage, 然后把 fsimage 文件上传到 active namenode 节点
active 挂的时候, standby 感知后, 转换为 active 角色, 生成一个新的 epoch(就是每次主备切换就加一, 表明现在谁是老大,在谁的任期内),因为 standby 是阶段性拉取 editlog的,所以肯定最新的一段editlog还没有作用于 fsimage, 需要拉取重放, 因为写 editlog 到 journal的时候, 只要大多数(比如总5个点,要成功写入3个点,总共3个点,要成功写入2个点)写入成功就认为成功了, 这样在拉取恢复的时候,各个journalnode 节点上的数据有可能不一致, 这时候就必须找到大多数里面 事务id最大的点作为基准, 这个事务id就类似于数据库中的 Log sequence number(简称LSN), 简单来讲, 就是要把 上一次checkpoint 的(LSN) 到 redo 日志里面最大的 (LSN)这之间的 日志进行重放redo,合并到fsimage。
假设一种情况, 老的active节点,是因为网络问题,连接不上 zookeeper, 然后被认为已经死了,其实是假死,这时候网络恢复了, 还认为自己是 leader, 往 journalnode里面写editlog日志, 发现现在已经是别人的天下了(epoch number已经加1了),自己的epoch number已经过时了,就把自己降级为 standby,做standby 角色该干的事情。
为什么要在 secondnamnode 上合并, 主要是为了减轻 namenode的压力, namenode有很多其他的事情要干呢。
操作
-
hadoop-daemon.sh start journalnode, 启动 journalnode 集群,会根据你配置文件里面配置的机器上去启动 journalnode 集群
-
hdfs namenode -format, 格式化 namenode 命名空间
-
hadoop-daemon.sh start namenode,nn1 上启动 namenode
-
hdfs namenode -bootstrapStandby, nn2 同步nn1的元数据信息, 会把主节点上的 fsimage editlog目录拷贝过来
-
hadoop-daemon.sh start namenode, nn2 上启动 namenode
-
启动 zk 集群 hdfs zkfc -formatZK 格式化 zkfc zk 中的目录 hadoop-daemon.sh start zkfc 各个namenode节点上启动dfszk failover controller, 先在哪台机器上启动,哪台就是active namenode
-
hadoop-daemon.sh start datanode 上传文件 测试 读写文件
-
测试 ha 将 active namenode进程kill, jps 进程号, kill, 将active namenode机器断开网络 service network stop
我们对集群进行以上的测试, 观察日志,会发现hdfs干的事情基本上就是前面描写的流程。